 返回首页
返回首页

CNCC|AI可以像孩子一样学习吗?
CNCC|AI可以像孩子一样学习吗?
CNCC2022将于12月8日至10日在贵州省贵阳市国际生态会议中心举办,今年CNCC技术论坛数量达到122个,内容涵盖了“计算+行业、人工智能、云计算、教育、安全”等30个方向。本文特别介绍将于12月10日举行的【多模态学习与认知——AI可以像孩子一样学习吗?】。
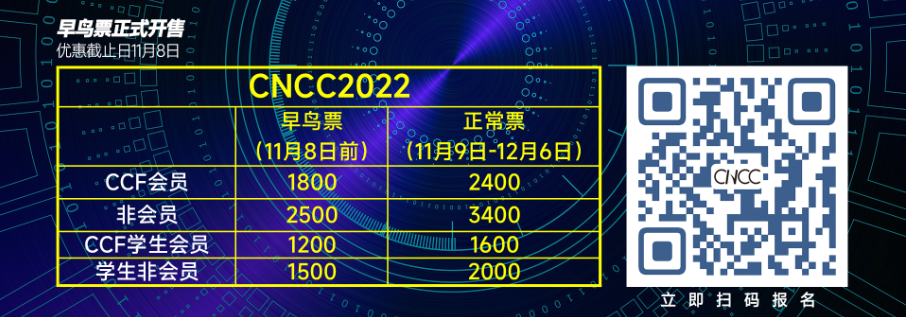
报名及了解更多技术论坛信息请识别下图二维码进入CNCC2022官网。目前早鸟票限时优惠报名正在进行,抓住机会立享大幅优惠!

随着国内外多模态预训练大模型(如OpenAI CLIP和DALL·E、文澜模型、女娲模型)的迅猛发展,越来越多的研究者认为AI的继续进步,需要突破语言、语音、视觉、图形等分门别类的研究,模仿人类孩子的学习方式,融合多种模态的信息,来认识世界。大脑是一个具备多模态信息处理的整体系统。通过对视觉、听觉、触觉等信息进行协同处理,其可以显著提升感知、交互、理解、决策等行为或任务的表现。在这个论坛上,我们有幸请到了从事多模态研究的脑科学与人工智能领域的一线科学家们,同大家一起探讨多模态学习背后的奥秘、前沿的发展和未来的趋势。
论坛安排
顺序 | 主题 | 主讲嘉宾 | 单位 |
1 | 多模态内容生成:技术进展及实践 | 何晓冬 | 京东 |
2 | AI赋能视觉内容创作 | 段楠 | 微软亚洲研究院 |
3 | 基于视觉信息编解码的深度学习类脑机制研究 | 何晖光 | 中国科学院自动化研究所 |
4 | 大规模多模态预训练的最新研究进展 | 卢志武 | 中国人民大学 |
5 | 基于人类行为的服务机器人导航算法设计 | 蒯曙光 | 华东师范大学 |
6 | 深入理解跨模态特征关联与融合——多模态预训练的研究与应用 | 张新松 | 字节跳动 |
论坛主席

文继荣
CCF常务理事
中国人民大学 信息学院院长/教授
现任高瓴人工智能学院执行院长和信息学院院长,大数据管理与分析方法研究北京市重点实验室主任。文继荣担任北京智源人工智能研究院首席科学家,北京市第十三届政协委员,中央统战部党外知识分子建言献策专家组专家,入选首批“北京高校卓越青年科学家计划项目”。曾任微软亚洲研究院高级研究员和互联网搜索与挖掘组主任。文继荣长期从事大数据和人工智能领域的研究,已在信息检索、数据挖掘、机器学习、数据库等领域国际著名学术会议和期刊上发表论文200余篇,总计引用15000余次,H-Index为57。担任AIRS 2016大会名誉主席、CCIR 2017大会主席、SIGIR 2018领域主席、SIGIR 2020程序委员会主席、WWW 2021领域主席等,担任ACM TOIS和IEEE TKDE的编委。
论坛共同主席

宋睿华
中国人民大学高瓴人工智能学院 长聘副教授
曾任微软亚洲研究院主管研究员和微软小冰首席科学家。近期研究兴趣为多模态理解、创作和交互。作为文澜项目的学术带头人,已发布系列图像-文本、视频-文本多模态预训练模型,并成功落地快手、OPPO等企业。发表学术论文90余篇,申请国际专利25项。担任SIGIR 2021短文的PC Chair,EMNLP 2021的Senior Area Chair,和Information Retrieval Journal的主编。她的算法完成了人类史上第一本人工智能创作的诗集《阳光失了玻璃窗》。
报告及讲者介绍

何晓冬
CCF企业与职业发展工作委员会副主任
CCF CTO Club主席
京东集团副总裁、京东AI研究院 常务副院长
二十多年来从事自然语言处理和语言与视觉多模态智能等人工智能领域的研究,是本领域世界级科学家。加入京东之前,何晓冬博士就职于美国微软雷德蒙研究院,担任首席研究员及深度学习技术中心负责人。他发表了200多篇论文,引用3万余次。他多次获得ACL杰出论文奖、IEEE SPS最佳论文奖等奖项,他还领导团队聚焦智能技术的前沿突破及智能服务与产品打造,大规模赋能政务、医疗、零售、金融等产业。他拥有清华大学学士学位及密苏里大学博士学位,同时在华盛顿大学(西雅图)等院校兼任教授。
报告题目:多模态内容生成:技术进展及实践
生成式AI(Generative AI),指通过AI技术创造全新的文本、图像、音频、视频、2D/3D交互内容等,是目前最活跃的技术方向之一。其在各种场景中也有广泛的应用前景,比如在社交媒体、内容创作、个性化营销、人机交互、数字人等。本演讲围绕生成式AI的技术研究及产业实践展开,结合在京东的应用实践,介绍包括商品文案生成、高表现力的语音合成、数字人交互内容生成等方面的进展。

段楠
微软亚洲研究院 首席研究员/研究经理
CCF杰出会员,中国科学技术大学兼职博导,天津大学兼职教授,主要从事自然语言处理、代码智能、多模态智能、机器推理等研究。
报告题目:AI赋能视觉内容创作
在内容即核心竞争力的时代,少数专业的内容创作者已经很难满足人们对多样化和个性化内容的巨大需求。如何降低内容创作的门槛和开销、提升内容创作者的生产力和创造力,已经成为人工智能领域中一个重要的前沿课题。本报告将介绍微软亚洲研究院在AI赋能视觉内容创作上的最新研究成果:女娲模型。我们希望这项技术能够赋能更多人,使得人人都有机会成为优质视觉内容的高效开发者和创作者。

何晖光
中科院自动化所 研究员
中国科学院大学岗位教授,上海科技大学特聘教授,中科院青促会优秀会员,建国七十周年纪念章获得者。先后获得国家科技进步二等奖两项,北京市科技进步奖两项,教育部科技进步一等奖,获中科院首届优秀博士论文奖,北京市科技新星,中科院“卢嘉锡青年人才奖”等奖项,其研究领域为人工智能,医学影像分析,脑-机接口等,其研究结果在IEEE TNNLS/TCYB/TMM/TNSRE, MedIA, NeuroImage, ICML, MICCAI等国内外核心期刊以及主流会议上发表文章180余篇。其是《自动化学报》及《中国图象图形学报》编委。
报告题目:基于视觉信息编解码的深度学习类脑机制研究
基于视觉信息编解码的深度学习类脑机制研究 摘要(200字):深度学习是否类脑?目前并没有统一的认识。对深度学习的类脑机制研究将有助于加深理解深度学习。我们将从视觉信息编解码的角度出发,建立从人类视觉系统与外界视觉刺激信息之间的映射模型,探索大脑视觉信息处理的过程和机理,希望利用机器智能实现对人类视觉感知功能的模拟,从而提升计算机处理视觉信息的能力。我们将介绍课题组在视觉信息编解码方面的系列工作,相关工作发表在IEEE TNNLS/TMM, Information Fusion, Pattern Recognition, AAAI上,并被MIT Technology Review头条报道。

卢志武
中国人民大学高瓴人工智能学院 教授
2005年毕业于北京大学数学科学学院信息科学系,获理学硕士学位;2011年毕业于香港城市大学计算机系,获PhD学位。主要研究方向为机器学习、计算机视觉等。设计首个公开的中文通用图文预训练模型文澜BriVL。以主要作者身份发表学术论文90余篇,其中在Nat Commun、TPAMI、IJCV等国际期刊和ICML、ICLR、NeurIPS、CVPR、ICCV等国际会议上发表论文50余篇。指导的学生获得2021年CCF优博、2021年百度奖学金。担任CCF生物信息学专委会委员。担任NeurIPS、ICML、ICLR、ICCV、CVPR、AAAI、IJCAI等国际顶级会议的(资深)程序委员。
报告题目:大规模多模态预训练的最新研究进展
大规模多模态预训练在经过爆发式发展后,目前处于“啃硬骨头”的阶段,更多关注落地应用、可解释性、交叉研究等。我们在2021年设计并训练了大规模中文通用图文预训练模型文澜BriVL,在跨模态检索、视频剪辑、图文生成等任务上均取得出色表现。2022年以来,我们重点研究多模态预训练模型的可解释性、类脑分析、连续训练等关键问题。本报告将详细介绍我们在大规模多模态预训练上取得的最新研究进展,并对未来发展趋势做必要的展望。

蒯曙光
华东师范大学心理与认知科学学院 教授
视觉空间认知和虚拟现实实验室负责人。蒯曙光博士主要使用数学和工程建模的方法研究人类认知交互行为。曾以第一或通讯作者在Nature Neuroscience, Nature Human Behavior, Current Biology, Plos Biology, Journal of Neuroscience, Psychological Science等国际知名心理学与神经科学杂志发表多篇的论文。蒯曙光博士先后主持了包括国家自然科学基金优秀青年基金在内的多个国家项目。
报告题目:基于人类行为的服务机器人导航算法设计
在智能时代中,服务机器人将成为人类生活中重要的伴侣。让机器人理解并学习人类的行为是让机器人融入到人类社会的关键。虽然心理学和社会学等相关学科对人类行为进行了长期的研究,但是多数研究仍停留在概念层面上的描述。我们的研究构建了基于虚拟情景下的人类行为实验平台,通过定量化的实验和数学建模的方法,量化人类社会交互的行为,并将其算法化,应用到机器人的空间导航任务中,从而有效的提升了服务机器人的社会友好性。

张新松
字节跳动AI Lab 研究员
博士毕业于上海交通大学计算机系,主要从事自然语言处理、预训练语言模型、多模态语言模型的研究。在ICML,TKDE,ACL,AAAI,EMNLP,NAACL等国际会议期刊上发表多篇学术论文。目前在字节跳动AI Lab进行语言模型和多模态语言模型的研究和应用,相关工作在多个实际业务场景中落地应用。
报告题目:深入理解跨模态特征关联与融合——多模态预训练的研究与应用
随着人工智能相关技术的快速发展,以Transformer为代表的通用骨干网络在视觉、NLP领域的诸多任务上取得了广泛的成功。我们认为,在此基础上的跨模态特征关联与融合是人工智能向“人类智能”迈进的下一个挑战。因此,我们深入研究跨模态特征关联方法,提出了多粒度视觉语言模型(X-VLM)、图片和文本统一生成模型(Davinci)等具有较强跨模态特征融合能力的模型。我将介绍字节跳动AILab在多模态预训练领域的系列研究工作及其实际应用。


CNCC是级别高、规模大的高端学术会议,探讨计算及信息科学技术领域最新进展和宏观发展趋势,展示计算领域学术界、企业界最重要的学术、技术成果,搭建交流平台,促进科技成果转换,是学术界、产业界、教育界的年度盛会。今年邀请嘉宾包括ACM图灵奖获得者、田纳西大学教授Jack Dongarra,以及高文、管晓宏、江小涓、钱德沛、徐宗本、张平等多位院士及专家,还有七百余位国内外名校学者、名企领军人物、各领域极具影响力的业内专家,CNCC在计算领域的水准及影响力逐年递增。本届CNCC的主题是:算力、数据、生态。
CNCC2022将汇聚国内外顶级专业力量、专家资源,为逾万名参会者呈上一场精彩宏大的专业盛宴。大会期间还将举办“会员之夜”大型主题狂欢活动,让参会者畅快交流,燃爆全场。如此盛会,岂能缺席!等你来,马上行动,欢迎参会报名!











