

在过去的两年里,为了满足机器学习的需要,特别是深度神经网络的需要,出现了一股对创新体系架构研究的热潮。我们已经在《The Next Platform》中报道了无论是用于训练侧还是推理侧的许多架构可选方案,并且正是因为所做的这些,我们开始注意到一个有趣的趋势。一些面向机器学习市场定制 ASIC 的公司似乎都在沿着同一个思路进行开发——以存储器作为处理的核心。
存储器内处理(PIM)架构其实不是什么新东西,但是因为存储器内相对简单的逻辑单元很好地迎合了神经网络的训练需求(特别是卷积网络),所以存储器正变成未来下一个平台。我们已经介绍过了很多公司的深度学习芯片,比如 Nervana Systems(2016 年被英特尔收购)和 Wave Computing,以及其它有望碾压 AlexNet 等 benchmark 的新架构,存储器都是其性能与效率的关键驱动因素。
今天,我们还要为这种存储器驱动的深度学习体系架构家族再介绍一个新成员。那就是 Neurostream,它由博洛尼亚大学提出,在某些方面与 Nervana、Wave、以及其它采用下一代存储器(比如 Hybrid Memory Cube (HMC) 和 High Bandwidth Memory (HBM))的深度学习架构很相似。而且该架构还提供了一种新思路,可以进一步深入了解我们刚才提到的那些公司是如何设计深度学习架构的。在过去的介绍里,我们已经从 Nervana、Wave 等发布的架构中提取出了一些设计细节,而这次架构的设计团队为我们带来了有关为什么存储器驱动型设备将会成为未来深度学习定制硬件主流更深入的见解。
「虽然卷积神经网络是计算密集型算法,但它们的可扩展性和能量效率被主存储器极大地限制住了,而这些网络中的参数和通道都比较大,所以都需要存储在主存中。鉴于上述原因,仅仅改进卷积网络加速器的性能和效率而不考虑主存储器的瓶颈将会是一个错误的设计决策。」
Neurostream 把它的存储器内处理方法用在扩展卷积神经网络上。该设计采用了一种 Hybrid Memory Cube 的变种,他们称之为「Smart Memory Cubes」。「Smart Memory Cubes」增强了被称为 NeuroCluster 的多核 PIM 平台。NeuroCluster 采用了基于 NeuroStream 浮点协处理器(面向卷积密集型计算)和通用处理器 RISC-V 的模块化设计。他们同样也提到了一种易于 DRAM 阵列化的机制及其可扩展的编程环境。该架构最吸引人的地方在于它用仅占晶片面积 8% 的 HMC 获得了 240GFLOPS 的性能,而其总功耗仅为 2.5 瓦。
「该平台能够以较小的系统功耗使得卷积神经网络计算任务能完全下放到存储器组中。这意味着主 SoC 中的计算逻辑能够被释放出来干其它事。而且,相对于一个基本 HMC 系统,其额外的开销几乎可以忽略不计。」
该设计团队正在大肆宣传其 Neurostream 架构的每瓦特性能指数。「在单个三维堆叠封装中我们达到了每瓦特 22.5GFLOPS(每秒浮点计算数 22.5G 次)的计算能量效率,这是当前能买到最好 GPU 性能的 5 倍以上。」他们同样提到「少量的系统级功耗升高和可以忽略不计的面积增长使得该 PIM 系统成为一种既节约成本又高效利用能量的解决方案,通过一个连接 4 个 SMC 的网络,其可以轻松扩展到 955 GFLOPS。」他们用来对比的 GPU 是 Nvidia Tesla K40,该 GPU 在 235 瓦功率下可以达到 1092 GFLOPS 的处理速度。「Neuro 阵列可以在 42.8 瓦达到 955GFLOPS,且超过了其对手 4.8 倍的能量使用效率,」该团队同时评论说,由于降低了对串行链路的需求,该架构还可以扩展至更多节点。
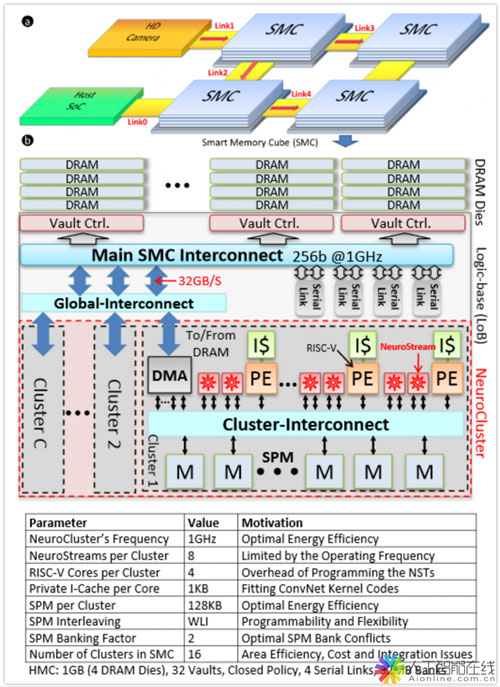
Neurostream 的创造者们期望通过进行一些面向应用的调优和降低算术计算精度的方法来使它的能效对比获得进一步增长。就像他们着重提到的,「降低计算精度有望使功耗降低达 70%。」在他们的下一次改进里,他们将着重在硅片上实现带有四个 NeuroClusters 的架构,这将使它能够监控其自身是如何反向传播和训练的。
我们已经介绍过了许多协处理器、ASIC、GPU、以及采用针对深度学习框架进行额外软件优化的 x86 处理器的性能和效率的 benchmark 比分。尽管我们对这些都半信半疑,尽我们可能地去对比,但时间最终会告诉我们哪种体系架构会最终胜出。这里想说的不在于 benchmark 比分,而在于体系结构本身。Neuro 阵列就像 Nervana、Wave、以及其它方法一样,都把 HMC 和 HBM 用到了极致——利用有限的存储器内处理能力,结果已经差不多能很好地处理卷积神经网络的计算了。
不仅如此,对该类架构的更深入观察,还能帮助我们更好地评估我们提到的机器学习芯片初创公司正在做的事。我们期待经过初创公司和学术研究的共同努力,2017 年将开辟设计许多在深度学习框架领域内的存储器驱动型处理器。



