



2022年10月16日,中国计算机学会青年计算机科技论坛(CCF YOCSEF)武汉分论坛举办了线下技术论坛(论坛编号:CCF-YO-22-WH-3FT)。本次论坛以“人工智能如何助力跨媒体融合?”为主题,邀请了华中科技大学、武汉大学、合肥工业大学、华为武汉研究院、武汉理工大学的专家和学者作为论坛嘉宾进行发言和思辨点讨论。本次论坛由YOCSEF武汉学术秘书、武汉大学副教授肖晶,YOCSEF武汉通讯AC、江汉大学教授李登实共同担任执行主席;YOCSEF武汉AC、北京联合伟世科技股份有限公司华中区域销售总监吴佳,YOCSEF武汉通讯AC、江汉大学讲师刘哲共同担任线上执行主席;武汉大学,江汉大学,以及江汉大学人工智能第二党支部为本次论坛提供了支持。本期技术论坛邀约人工智能领域相关的专家学者,针对“人工智能如何助力跨媒体融合?”进行主题讨论,分析人工智能在跨媒体融合领域面临的主要挑战,探讨跨媒体融合技术在应用领域中面临的需求和问题,探索跨媒体融合技术发展面临的瓶颈问题,把握协同跨媒体融合未来发展的方向和机遇。

图1 “人工智能如何助力跨媒体融合”技术论坛
论坛的引导发言环节邀请了3位嘉宾,分别是:华中科技大学教授刘琼、武汉大学教授王正以及合肥工业大学教授王扬。刘琼教授带来了题为”交互式媒体方法与应用“的引导发言。刘琼教授首先提出多媒体数据维度的提高改变了人机交互的形式,目前的难题在于如何让机器能像人一样,可以对周围的环境,以及对人的意图进行理解。进而从研究角度上,刘教授团队把现有的主要工作提炼为高位图像的采集与感知表达、视觉计算与空间认知、意图理解与交互重构等三个方面。接着,刘教授从三维空间信号的描述角度,提出常用方法包括计算法和感知法。从感知法出发,具体的方法可以通过多角度的相机阵列、深度传感器阵列,多角度光源发生器等进行三维空间信号的采集。然而,采用这些数据采集方法,最重要的是需要尽可能地对物理客观世界进行刻画。因此,刘琼教授所在实验室采用的球形自研数据采集装置,可以模拟各种光照条件,并进行毫秒级控制。并且,在多视角视频采集通过环形相机阵列实现,创新性地提出了金字塔形采集阵列。随后,刘教授在深度感知的视频编码方面,提出从静态向动态发展的方法;在多试点融合计算方面,提出采用数据与模型联合驱动的方法,通过空间立体几何和人工智能数据驱动的共同实现多视点融合。然后,刘教授介绍了焦栈图像具有立体完整呈现场景信息、给用户自用控制观看场景深度的优势,是未来多媒体技术一个发展方向,但是高度数据冗余会造成存储、数据表示方面的问题。因此,刘教授团队针对焦栈图像,提出了的基于表示模型的编码和基于表示魔方的渲染方法。最后刘琼教授从人眼视觉特性的角度出发,尝试将人类视觉认知机理引入到视觉编码表示领域,提出了基于RGB-D视频的视觉显著度方法。该项研究为多维度视觉信息处理领域相关研究提出了新的思路。

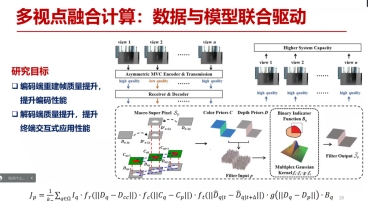
图2 基于RGB-D视频的视觉显著度方法
随后,来自武汉大学计算机学院的王正教授,进行了题为“恶劣环境下多媒体内容理解、检测、检索”的引导发言。首先介绍了图像语义分割和内容理解的相关背景,并分析了其研究价值和应用领域,包括自动驾驶系统、无人机应用以及穿戴式设备应用。图像语义分割和内容理解在良好图像环境下可以取得不错的效果,但实际应用中拍摄到的图像往往难以保证图像环境场景的质量。针对恶劣环境下的语义分割任务,王教授提出以下几种方法提高该任务的性能:(1)在数据集方面,首先获取大量标注图像,分析了恶劣环境下降低内容理解性能的因素,并进行了针对性的方法改进,通过增加一个中间层提高了图像内容理解的性能;(2)在域适应方面,可利用数据特性从简单到复杂环境的适应,通过空间域和时间域的diffusion来提高性能;(3)提出分布的跨时间一致性和背景跨帧一致性,利用良好环境和恶劣环境间的一致性来提供算法性能,通过融合区域分布和背景的先验知识提供内容理解性能。(4)通过分析恶劣环境中的光照变化来改进方法,提升算法性能。(5)针对地面与卫星遥感场景,提出在地面照片和卫星遥感照片之间,添加无人机拍摄照片,通过无人机域把地面图像域和卫星图像域串联起来,以获得更好的理解结果。


图3 恶劣环境下多媒体内容理解、检测、检索
作为最后一位引导发言嘉宾,来自合肥工业大学多媒体实验室的王杨教授进行了题为“全局纹理结构角度下的图像修复”的引导发言。王教授首先介绍了图像补全的相关背景和研究现状,并介绍了图像补全的应用领域,包括图片编辑、照片修复、目标移除等。深度学习的图像补全方法,比如基于CNN只考虑局部图像信息,而基于注意力机制的方法又考虑图像的所有区块信息,独立计算不同区域信息可能会误导补全的结果。针对基于深度学习的图像补全所存在的问题,王杨教授指出可以从纹理和结构的角度来进一步提升图像内容的理解和补全。为此,王教授提出了基于结构和纹理的模型,根据结构约束生成更好的纹理语义,贡献有以下两点:(一)利用transformer编码模型根据纹理参考信息来获取整幅图像的语义相关性并探索图像的全局结构,(二)再用transformer模型重构图像的每一块区域,从而实现全局的低频和高频信息的补全。最后王教授用一句话总结了他今天分享的图像补全工作的核心思想,即“通过人工智能技术帮助不同媒体进行信息补全和协同。”

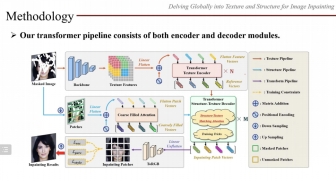
图4 全局纹理结构角度下的图像修复
在思辨环节,参与论坛的所有专家和老师就以下三个议题进行了激烈的探讨:(1)媒体信息处理技术的必经之路是什么?(2)单一媒体信息处理技术的叠加是否等同于媒体信息融合?(3)基于人工智能的跨媒体融合技术路在何方?这三个问题也是目前人工智能助力跨媒体融合需要面对和解决的问题。
对于“媒体信息处理技术的必经之路是什么?”这个问题的思辨,专家和老师们讨论了下列子问题:1.1在媒体信息技术中常提及:“多媒体”、“跨媒体”、“融媒体”,“全媒体”等名词,这些名词是概念炒作吗?1.2目前媒体信息技术最需要在“多媒体”、“跨媒体”、“融媒体”,还是“全媒体”上开展研究?
武汉大学王正教授认为,从历史和发展的角度来说,多媒体从一开始做的编解码,到内容理解,以及到现在的跨媒体、全媒体内容分析,这些是与社会发展、经济发展息息相关的。这些概念所涉及到的技术的发展需要和社会需求相结合。
华为武汉研究所高丽主任工程师认为,不同媒体之间的信息具有一定的相关性,可以通过这些相关性将不同形态的媒体数据串联起来。就融媒体而言,目前业界主流的技术采用的是音视频融合。全媒体则是一种基础建设方面的概念,目前还处于发展中。
合肥工业大学王杨教授认为,跨媒体的目的是为了融合。目前适合从跨媒体、融媒体的角度开展研究,需要解决何时、何地、采用什么方法进行融合的问题,如何在最恰当的时间和地点消除多种媒体信息中的不确定性。
武汉理工大学钟忺副教授认为,全媒体是目标,融媒体是研究发展的必经阶段。在低光照场景下,视觉摄像头能获取的信息非常少,此时适合采用深度信息或者红外信息来做媒体数据的融合和补全。


图5 思辨问题1:媒体信息处理技术的必经之路是什么?
在“单一媒体信息处理技术的叠加是否等同于媒体信息融合?”的问题上,来自不同领域和方向的专家、老师们也各抒己见,讨论了以下子问题:2.1使用单一媒体信息处理技术的叠加方式是否能有效实现媒体融合?2.2媒体融合主流技术有哪些,其中的关键技术包含哪些?
武汉大学的王正教授认为,不同媒体的信息有效性是不同的,具有不同的侧重性和倾向性,因而简单的叠加效果不明显。
华为武汉研究院的高丽主任工程师认为,在音频领域中,能够称为多媒体融合的就是音视频结合。音频受环境的影响非常大,单纯靠音频实现场景理解非常困难。视频信息可以给音频信息参考,音频信息可以和视频信息进行融合。目前在音频领域主流的工业界方法还是单一的音视频叠加。之所以目前还没有往融合的方向做训练,原因在于音频和视频信号的数据维度是割裂的,联合做训练的难点不一定是技术性的,而在于如何做选择、剔除干扰信息。
合肥工业大学王杨教授认为,融合方式分为三种。一是早期融合,即先把数据做叠加,然后再放入到模型中进行训练;二是晚期融合,即先单独把数据做特征提取,然后在特征层面上再做融合;三是在数据处理过程中进行融合,但是技术难点在于计算复杂度,数据维度较高时,计算效率难以接受。由于不同模态的媒体数据在数据处理的目标也是不一样,使得衡量各个模态的不同目标,并能进行统一融合是一个需要考虑的重要问题。
武汉理工大学钟忺副教授认为,早期的媒体数据融合方式是在相对粗粒度层面上的数据融合,具体的融合方式可以相对简单,例如加法、乘法、加权拼接等。但随着融合技术的发展,可以将更多人工智能技术,例如Vision Transformer等用于媒体数据融合。他同样赞同王杨教授的观点,不同数据的处理目标不同,融合的难点仍然是如何针对不同数据特性设计统一融合的方法。


图6 思辨问题2:单一媒体信息处理技术的叠加是否等同于媒体信息融合?
在“基于人工智能的跨媒体融合技术路在何方?”的问题上,专家和老师们分析和讨论了以下两个子问题:3.1人工智能技术是否是跨媒体融合的催化剂? 3.2. 跨媒体融合技术的新需求是否能反哺人工智能技术的革新?
武汉大学王正教授认为,如自然语言处理、计算机视觉等相关领域的技术可以对多媒体融合起到更加重要的作用。由于目前不同媒体之间的研究差异很大,通过人工设计的融合方法很难取得理想的效果,因此需要借助人工智能技术。换句话说,人工智能技术推动了跨媒体融合技术的发展。
合肥工业大学王杨教授认为,人工智能技术不仅能在跨媒体融合中解决很多传统技术无法处理的问题,也能够帮助研究者更好地理解跨媒体融合中的问题。
武汉理工大学钟忺副教授认为,多媒体数据形态的增加与发展为人工智能模型和技术的发展提供了更多新的数据形态,多媒体和人工智能是相辅相成的。
华为武汉研究院的高丽主任工程师认为,多媒体领域的新需求可以在一定程度上推进人工智能技术的进步。音视频联合领域相对于视频和图像领域发展更慢。以往的音频处理技术通常更依赖传统方法。近年来音频降噪、语音识别等领域的突破加速了音视频融合的发展。


图7 思辨问题3:基于人工智能的跨媒体融合技术路在何方?
图8 参会人员合影
本次论坛历时三个小时,通过引导发言、论坛思辨,辨明了跨媒体融合领域在人工智能时代遇到的新问题和困惑,分析跨媒体融合在发展过程中面临的主要挑战,探讨跨媒体融合在应用中存在的若干重要问题,探索了跨媒体融合技术的未来发展方向,将人工智能技术赋能跨媒体融合,加快了跨媒体融合技术的发展。















